| Module name: | ASIAN |
| Module identifier: | RM_ASIAN |
| Filling methods supported: | FM_OMNIFONT |
| Filters supported: | should not be used |
| Trade-off supported: | for CCJK, see below |
| Training file supported: | no |
This module can be purchased as an add-on to either the Professional Recognition Kit or the Professional OCR Kit, or as a separate Asian Kit. Its inclusion in your application must be covered by distribution licensing. See the topic on Licensing in the General Information help system.
Application areas
This module provides recognition services for four Asian languages with horizontal or vertical text direction; these languages are Japanese, Korean and Chinese – Traditional and Simplified (generally referred as CCJK). In addition this module recognizes Arabic text. It can handle short embedded English texts within either CCJK or Arabic text. Arabic language is accessible from version 19.2.
See the detailed information about the CCJK characters known by this module.
CCJK text can be horizontal and left-to-right (WT_FLOW) or vertical - character flow top-to-bottom with line flow from right-to-left (WT_VERTTEXT).
Texts embedded in vertical texts can have three orientations: vertical (neon), right-rotated and side-by-side. The latter is usually limited to three characters, and is most often used for Arabic numerals. The output converters of RecAPIPlus transform all such embedded texts to the right rotation.
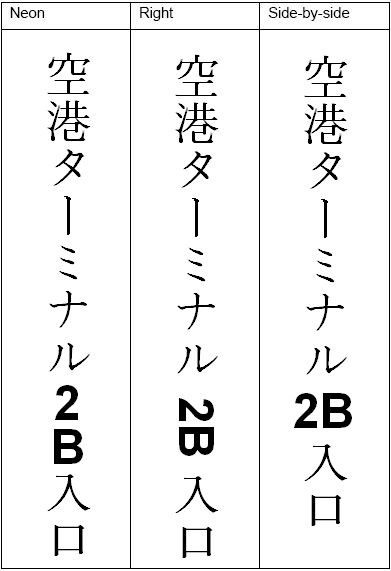
The orientation of CCJK text is auto-detected on pages where user zones have not been inserted or on WT_AUTO user zones. Auto-detection runs zone-by-zone, so pages with both horizontal and vertical text blocks (such as for picture captions) can be handled.
Digital camera input can be used for Asian-language input, but the automatic 3D deskewing is not useful in these cases. Manual 3D deskew is available via the Scanner Enhancement Technology Tools (SET Tools), which is a part of RecAPIPlus and the Image View Visual Control (for more information see the IPRO and Visual Toolbox documentation systems).
Table zones can be inserted onto Asian pages, but if the OCR cannot detect a table within such a zone, the zone is likely to produce zero recognition results.
Language handling
The Asian language handling differs somewhat from that for Western languages. Spell checking, editor display and verification are not available for Asian languages. In addition only one Asian language should be set for recognition and Western languages should not be set alongside an Asian language (except English in one case - see next paragraph).
Asian OCR Engine can recognize short English texts embedded in any Asian text. In CCJK OCR, it works in default without English language to be set. If embedded texts are in other Latin-alphabet languages, their recognition is also possible, however accented characters may not always be handled correctly. In the case of Arabic OCR, English language MUST be set for embedded text recognition of any Latin-alphabet language. (See also Thai, Vietnamese and Hebrew language handling details.)
IMPORTANT NOTE: For the correct working of the Asian Recognition Module, the selected Asian language should be set before the preprocess operation.
NOTE: Of course the above mentioned language selection manner does not refer to Single Language Detection.
Conditions
The ideal font point size for CCJK language body text is 12 points ("small four" in Chinese size name), scanned at 300 dpi, resulting in characters with around 48 x 48 pixels. The minimum pixel count is about 30 x 30, that is 7.5 points at 300 dpi ("six"). For characters smaller than this, 400 dpi should be used.
When user zones are used, it is recommended to create homogeneous user zones as much as possible, because they may give better results. It is especially important in the case of Asian languages. WT_AUTO zones can be inhomogeneous.
Deskew and orientation
The deskew and orientation detection work in a different way for Arabic language than in the case of other languages. The working of both operations can be adjusted through settings (Kernel.Img.Deskew.EnabledForArabic and Kernel.Img.Rotation.EnabledForArabic). If these settings are FALSE (by default), the AUTO methods (DSK_AUTO, ROT_AUTO) of these operations for Arabic language equal to the case when they are switched off (DSK_NO, ROT_NO). If the settings are TRUE, or the deskew and orientation are not set to AUTO, the working of these methods are the same for both the Arabic and the Western cases.
CCJK trade-off
There are 3 engines inside this module for CCJK languages, which are accessible from OmniPage CSDK 19.20.
- Full CCJK Engine provides the CCJK OCR being before v19.20.
- Fast CCJK Engine provides a faster but less accurate one, mainly for embedded solutions.
- Voting CCJK Engine combines the above two engines for a better accuracy. Of course, this is slower than Full CCJK. This engine is supported on: Windows.
NOTE: Fast and Voting CCJK engines are recommended to use mainly for Japanese language.
These engines can be controlled by settings. Setting trade-off to TO_FAST selects Fast CCJK Engine for running. Setting trade-off to TO_ACCURATE and Kernel.OcrMgr.PreferAccurateEngine selects Voting CCJK Engine for running. Otherwise, Full CCJK runs.
Character attributes
The character attributes, such as bold and italic styling, cannot be retrieved for Asian text, nor for embedded English text.
Confidence data and choices
Recognition results can be saved to memory as a LETTER array, making the confidence data and alternate character choices available for Asian languages for the first time.